>The Java-chip thing proved more difficult to realize than anticipated
I've been very slowly upping my Java-fu over the past year or so to crack into the IC market here in the Nordics. Naturally I started by investigating the JVM and its bytecode in some detail. It may surprise a lot of people to know that the JVM's bytecode is actually very, very much not cleanly mappable back to a normal processor's instruction set.
My very coarse-grained understanding is: If you really want to "write once, run anywhere", and you want to support more platforms than you can count on one hand, you eventually kind of need something like a VM somewhere in the mix just to control complexity. Even moreso if you want to compile once, run anywhere. We're using VM here in the technical sense, not in the Virtualbox one - SQLite implements a VM under the hood for partly the same reason. It just smooths out the cross-compilation and cross-execution story a lot, for a lot of reasons.
More formally: A SQLite database is actually a big blob of bytecode which gets run atop the Virtual DataBase Engine (VDBE). If you implement a VDBE on a given platform, you can copy any SQLite database file over and then interact with it with that platform's `sqlite3`, no matter which platform it was originally built on. Sound familiar? It's rather like the JVM and JAR files, right?
Once you're already down that route, you might decide to do things like implement things like automatic memory management at the VM level, even though no common hardware processor I know has a native instruction set that reads "add, multiply, jump, traverse our object structure and figure out what we can get rid of". VDBE pulls this kind of hat trick too with its own bytecode, which is why we similarly probably won't ever see big hunking lumps of silicon running SQLiteOS on the bare metal, even if there would be theoretical performance enhancements thataways.
(I greatly welcome corrections to the above. Built-for-purpose VMs of the kind I describe above are fascinating beasts and they make me wish I did a CS degree instead of an EE one sometimes.)
It's not common, as only one was ever made, but the Lisp processor described in Sussman and Steele's paper "Design of LISP-based Processors, or SCHEME: A Dielectric LISP, or Finite Memories Considered Harmful, or LAMBDA: The Ultimate Opcode", had built-in, hardware-implemented garbage collection.
I was once at a meetup for Lisp hackers, and discussing something or another with one of them, who referred to Lisp as a "low-level language". When I expressed some astonishment at this characterization, he decided I needed to be introduced to another hacker named "Jerry", who would explain everything.
"Jerry" turned out to be Gerald Sussman, who very excitedly explained to me that Lisp was the instruction set for a virtual machine, which he and a colleague had turned into an actual machine, the processor mentioned above.
I remember seeing a Java microprocessor for sale years ago. It claimed that the CPUs native instruction set is Java bytecode.
I can't find that exact microcontroller that I remember, I think the domain is gone, but there are other things like this, including some FPGA cores which make the same claim that I remember from that microcontroller I read about in the early 2000s. I wonder how those would perform compared to a JVM running on a traditional instruction set on the same FPGA.
nah it was a processor whose native instruction set was java bytecode. it garbage collected natively, and all the other stuff. It was not Jazelle, nor was it an ARM CPU which interpreted bytecode and ran it.
I think it was the "aJile" processor listed in your final link, but I'm not 100% sure. It was over 20 years ago that I read about it and was about to buy a development kit when I got pulled off of all java work I was doing.
Lynn Conway, co-author along with Carver Mead of "the textbook" on VLSI design, "Introduction to VLSI Systems", created and taught this historic VLSI Design Course in 1978, which was the first time students designed and fabricated their own integrated circuits:
>"Importantly, these weren’t just any designs, for many pushed the envelope of system architecture. Jim Clark, for instance, prototyped the Geometry Engine and went on to launch Silicon Graphics Incorporated based on that work (see Fig. 16). Guy Steele, Gerry Sussman, Jack Holloway and Alan Bell created the follow-on ‘Scheme’ (a dialect of LISP) microprocessor, another stunning design."
The original Lisp badge (or rather, SCHEME badge):
Design of LISP-Based Processors or, SCHEME: A Dielectric LISP or, Finite Memories Considered Harmful or, LAMBDA: The Ultimate Opcode, by Guy Lewis Steele Jr. and Gerald Jay Sussman, (about their hardware project for Lynn Conway's groundbreaking 1978 MIT VLSI System Design Course) (1979) [pdf] (dspace.mit.edu)
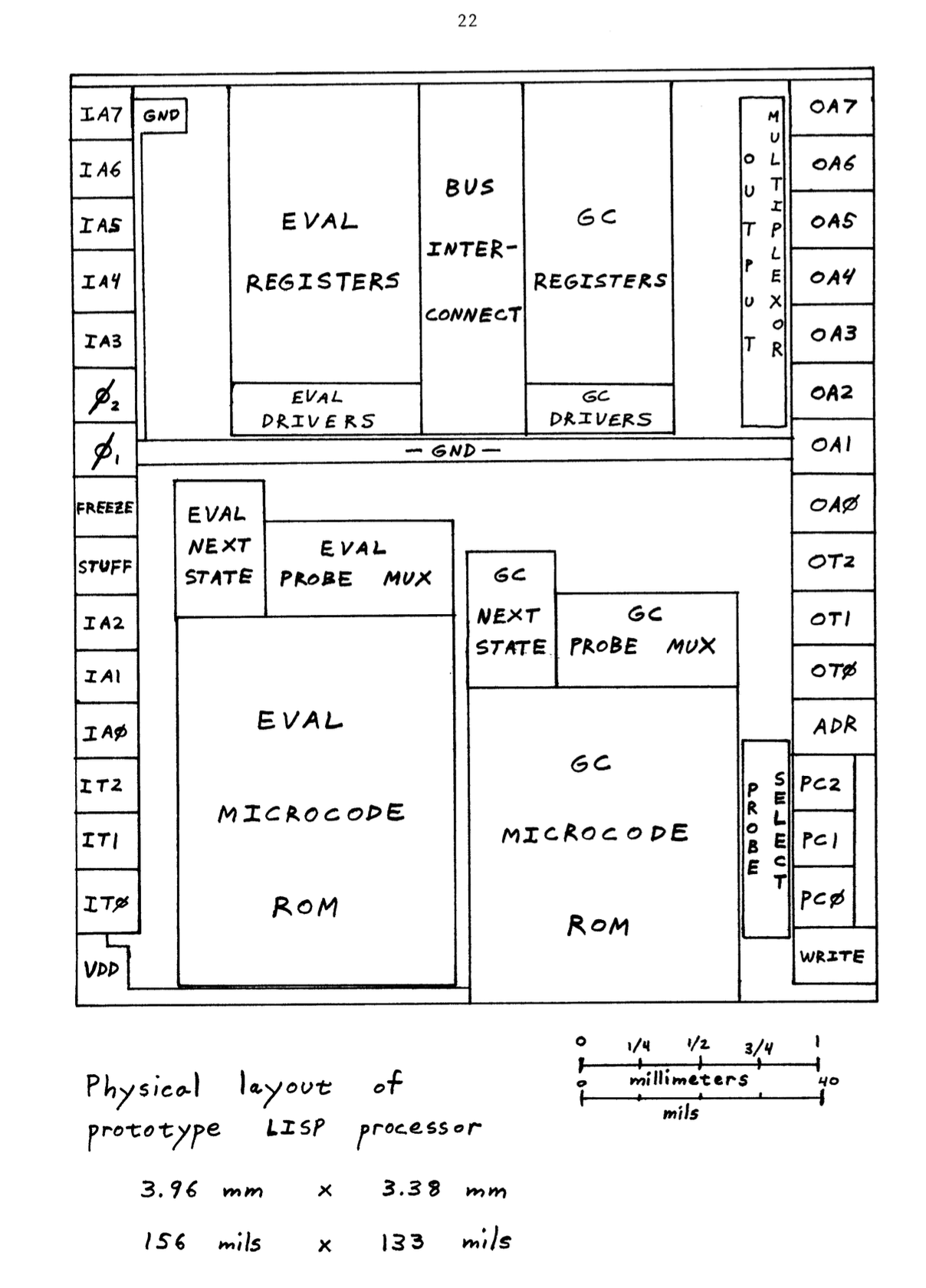
The Great Quux's Lisp Microprocessor is the big one on the left of the second image, and you can see his name "(C) 1978 GUY L STEELE JR" if you zoom in. David's project is in the lower right corner of the first image, and you can see his name "LEVITT" if you zoom way in.
Here is a photo of a chalkboard with status of the various projects:
The final sanity check before maskmaking: A wall-sized overall check plot made at Xerox PARC from Arpanet-transmitted design files, showing the student design projects merged into multiproject chip set.
One of the wafers just off the HP fab line containing the MIT'78 VLSI design projects: Wafers were then diced into chips, and the chips packaged and wire bonded to specific projects, which were then tested back at M.I.T.
We present a design for a class of computers whose “instruction sets” are based on LISP. LISP, like traditional stored-program machine languages and unlike most high-level languages, conceptually stores programs and data in the same way and explicitly allows programs to be manipulated as data, and so is a suitable basis for a stored-program computer architecture. LISP differs from traditional machine languages in that the program/data storage is conceptually an unordered set of linked record structures of various sizes, rather than an ordered, indexable vector of integers or bit fields of fixed size. An instruction set can be designed for programs expressed as trees of record structures. A processor can interpret these program trees in a recursive fashion and provide automatic storage management for the record structures. We discuss a small-scale prototype VLSI microprocessor which has been designed and fabricated, containing a sufficiently complete instruction interpreter to execute small programs and a rudimentary storage allocator.
Here's a map of the projects on that chip, and a list of the people who made them and what they did:
Just 29 days after the design deadline time at the end of the courses, packaged custom wire-bonded chips were shipped back to all the MPC79 designers. Many of these worked as planned, and the overall activity was a great success. I'll now project photos of several interesting MPC79 projects. First is one of the multiproject chips produced by students and faculty researchers at Stanford University (Fig. 5). Among these is the first prototype of the "Geometry Engine", a high performance computer graphics image-generation system, designed by Jim Clark. That project has since evolved into a very interesting architectural exploration and development project.[9]
Figure 5. Photo of MPC79 Die-Type BK (containing projects from Stanford University):
The text itself passed through drafts, became a manuscript, went on to become a published text. Design environments evolved from primitive CIF editors and CIF plotting software on to include all sorts of advanced symbolic layout generators and analysis aids. Some new architectural paradigms have begun to similarly evolve. An example is the series of designs produced by the OM project here at Caltech. At MIT there has been the work on evolving the LISP microprocessors [3,10]. At Stanford, Jim Clark's prototype geometry engine, done as a project for MPC79, has gone on to become the basis of a very powerful graphics processing system architecture [9], involving a later iteration of his prototype plus new work by Marc Hannah on an image memory processor [20].
[...]
For example, the early circuit extractor work done by Clark Baker [16] at MIT became very widely known because Clark made access to the program available to a number of people in the network community. From Clark's viewpoint, this further tested the program and validated the concepts involved. But Clark's use of the network made many, many people aware of what the concept was about. The extractor proved so useful that knowledge about it propagated very rapidly through the community. (Another factor may have been the clever and often bizarre error-messages that Clark's program generated when it found an error in a user's design!)
9. J. Clark, "A VLSI Geometry Processor for Graphics", Computer, Vol. 13, No. 7, July, 1980.
[...]
The above is all from Lynn Conway's fascinating web site, which includes her great book "VLSI Reminiscence" available for free:
These photos look very beautiful to me, and it's interesting to scroll around the hires image of the Quux's Lisp Microprocessor while looking at the map from page 22 that I linked to above. There really isn't that much too it, so even though it's the biggest one, it really isn't all that complicated, so I'd say that "SIMPLE" graffiti is not totally inappropriate. (It's microcoded, and you can actually see the rough but semi-regular "texture" of the code!)
This paper has lots more beautiful Vintage VLSI Porn, if you're into that kind of stuff like I am:
A full color hires image of the chip including James Clark's Geometry Engine is on page 23, model "MPC79BK", upside down in the upper right corner, "Geometry Engine (C) 1979 James Clark", with a close-up "centerfold spread" on page 27.
Is the "document chip" on page 20, model "MPC79AH", a hardware implementation of Literate Programming?
If somebody catches you looking at page 27, you can quickly flip to page 20, and tell them that you only look at Vintage VLSI Porn Magazines for the articles!
There is quite literally a Playboy Bunny logo on page 21, model "MPC79B1", so who knows what else you might find in there by zooming in and scrolling around stuff like the "infamous buffalo chip"?
> It may surprise a lot of people to know that the JVM's bytecode is actually very, very much not cleanly mappable back to a normal processor's machine code or instruction set
I believe this is a very sensible decision: being too close to a real architecture would probably tie the bytecode to similar architectures too much and make it quite useless as opposed to compiling to an actual architecture.
The bytecode being abstract enough is likely a good thing to be able to achieve okay performance everywhere. Like, you wouldn't want the bytecode to specify a fixed number of registers.
What may also surprise many people thinking Java is a bloated language is that the Java bytecode is actually quite simple, straightforward to understand, clean and also very well documented. It's an interesting thing to look into, even for someone not involved day to day in some Java.
In the 6502 and Z80, "opcode" refers to the actual machine instruction executed by the CPU, represented by mnemonics (e.g., LDA, STA). Each mnemonic can map to multiple opcode values due to different addressing modes.
The 6502 has 56 mnemonics, mapping to about 151 unique opcodes.
The Z80 has about 80 distinct mnemonics, mapping to about 158 base opcodes, with extended opcodes (via CB, ED, DD, FD prefixes) pushing the total to around 500.
Java bytecode opcodes are symbolic instructions for a virtual stack machine, about 200 in total with a 1:1 mapping from mnemonic to opcode, and just an "wide" extended prefix to extend operand sizes, designed for portability rather than direct hardware execution.
Stack-based microprocessors tend to perform worse than register-based ones and I assume there wasn't a huge reason to develop a Java-on-chip for a "Java computer.” (1) It would have not run non-Java software easily and (2) the future of stack-based microprocessors wasn't as bright.
Sun also produced the MAJC[0] (Microprocessor Architecture for Java Computing) processor, a VLIW design. It was only used in one of Sun's graphic boards.
IIRC correctly the original Java VM was a stack based machine. That made sense when it was first created since a stack based machine is the simplest system you can create that run code and since it only need three registers, one for the instruction, one for the first data and one for the top of the stack for the other data. The problem is that you need to push and pop a lot from the stack during runtime which means more memory accesses and more time spent on gathering the data than on doing actual operations. That also underutilizes the processor registers since on a normal processor you would be using two data registers at most. This was one of the early issues with java running slowly on android and the reason of the creation of the Dalvik VM which was a register one.
You compile the stack based code into register code. It is, of course, easier to say than to do, but it is within the range of a skilled team, not absurdly complicated.
You can think about it on a really small scale:
PUSH 1
PUSH 2
PUSH 3
ADD
PUSH 4
MULT
ADD
is not that hard to conceptually rewrite into
STORE 1, r1
STORE 2, r2
STORE 3, r3
ADD r2, r3 INTO r2
STORE 4, r3
MULT r2, r3 INTO r2
ADD r1, r2 INTO r1
Of course, from there, you have to deal with running out of registers, then you're going to want to optimize the resulting code (for instance, generally small numbers like this can fit into the opcodes themselves so we can optimize away all the STORE instructions easily in most if not all assembly languages), but, again, this is all fairly attainable code to developers with the correct skills, not pie-in-the-sky stuff. Compiler courses do not normally deal directly with this exact problem, but by the time you finish one you'd know enough to tackle this problem since the problem since the problem that compiler courses do deal with is a more-or-less a superset of this problem.
oh okay, so you're not really running the original byte code. You're cross-compiling it to a different architecture effectively. That makes sense then!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I've been very slowly upping my Java-fu over the past year or so to crack into the IC market here in the Nordics. Naturally I started by investigating the JVM and its bytecode in some detail. It may surprise a lot of people to know that the JVM's bytecode is actually very, very much not cleanly mappable back to a normal processor's instruction set.
My very coarse-grained understanding is: If you really want to "write once, run anywhere", and you want to support more platforms than you can count on one hand, you eventually kind of need something like a VM somewhere in the mix just to control complexity. Even moreso if you want to compile once, run anywhere. We're using VM here in the technical sense, not in the Virtualbox one - SQLite implements a VM under the hood for partly the same reason. It just smooths out the cross-compilation and cross-execution story a lot, for a lot of reasons.
More formally: A SQLite database is actually a big blob of bytecode which gets run atop the Virtual DataBase Engine (VDBE). If you implement a VDBE on a given platform, you can copy any SQLite database file over and then interact with it with that platform's `sqlite3`, no matter which platform it was originally built on. Sound familiar? It's rather like the JVM and JAR files, right?
Once you're already down that route, you might decide to do things like implement things like automatic memory management at the VM level, even though no common hardware processor I know has a native instruction set that reads "add, multiply, jump, traverse our object structure and figure out what we can get rid of". VDBE pulls this kind of hat trick too with its own bytecode, which is why we similarly probably won't ever see big hunking lumps of silicon running SQLiteOS on the bare metal, even if there would be theoretical performance enhancements thataways.
(I greatly welcome corrections to the above. Built-for-purpose VMs of the kind I describe above are fascinating beasts and they make me wish I did a CS degree instead of an EE one sometimes.)